
Summary
We propose to illustrate how far BERT-type models can be considered as interpretable by design. We show that the attention coefficients specific to BERT architecture constitute a particularly rich piece of information that can be used to perform interpretability. There are mainly two ways to do interpretability: attribution and generation of counterfactual examples. In a first article, we showed how attention coefficients could be the basis of an attribution interpretability method. Here we propose to evaluate how they can also be used to set up counterfactuals.
Work presented in the previous article
Previously, the BERT [1] and DistilBERT [2] models have been mobilized to tackle the well-known problem of sentiment analysis. In particular, we have shown that the BERT and DistilBERT models contain within their architecture attention coefficients that can be at the heart of an attribution interpretability method. Starting from an initial text, a visualization of the weight assignment method was proposed. The more red the color, the higher the associated attention coefficient.

Figure 1 - Attention-Based token importance
We saw that the word groups "favorite movie", "it just never gets old", "performance brings tears", or "it is believable and startling" stood out. This explained well why the algorithm evaluated the review as positive and what was the semantic field at the root of this prediction. This work was done using the Hugging Face transformers library [3].
Interpreting through counterfactual generation
Another way to do interpretability is to generate counterfactual examples. According to Judea Pearl, counterfactual "involves answering questions which ask what might have been, had circumstances been different” [4]. Thus, the idea is to understand a prediction by generating a counterfactual example, resulting in an opposite prediction. In the context of natural language processing, it is therefore a matter of changing the right words in the review. In order to generate a counterfactual example, we propose the following methodology:
- Compute the attention coefficients of the tokens in a text corpus on each attention layer (6). The text corpus size must be statistically significant
- Perform token clustering based on their 6-dimensional representation
- Detect clusters associated with positively and negatively charged sentiment words
- Replace the tokens with the highest average attention with their "opposite token" in their "opposite cluster" This approach allows us to validate the interpretative strength of the tokens put forward by the attention coefficients, while illustrating what a close review would have been with an opposite sentiment. We apply the methodology on a corpus of 1000 reviews. The clustering method used is the hierarchical ascending classification (HAC) and gives 3 clusters. The obtained clusters and the counterfactual generation procedure can be represented in 2 dimensions as follows:
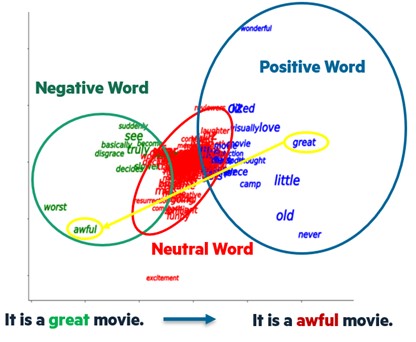
Figure 2 - Token clusters & replacements
We then generate the counterfactual example of the review tested earlier by changing 2 words:
favorite ➡ worst
This gives us the following counterfactual example:
“Probably my all time worst movie a story of selflessness sacrifice and dedication to a noble cause but its not preachy or boring . it just never gets old despite my having seen it some 15 or more times in the last 25 years . paul lukas performance brings tears to my eyes and bette davis in one of her very few truly sympathetic roles is a torment. the kids are as grandma says more like dressedup midgets than children but that only makes them more fun to watch . and the mothers slow awakening to whats happening in the world and under her own roof is believable and startling . if i had a dozen thumbs they’d all be up for this movie".
As the text is quite long, 2 tokens are not enough to change the feeling associated with the review. The probability score nevertheless drops significantly by 0.3pts. One way to assess the quality of the generated counterfactual examples is to evaluate the proportion of reviews in a corpus whose associated sentiment has changed. The result can be represented as a "counterfactual confusion matrix" as follows:
One way to assess the quality of the generated counterfactual examples is to evaluate the proportion of reviews in a corpus whose associated sentiment has changed. The result can be represented as a "counterfactual confusion matrix" as follows:

Table 1 - Counterfactual confusion matrix example
Where :
- X11 represents the share of reviews whose initial associated sentiment and the sentiment of the counterfactual example are positive; sentiment has remained the same
- X12 represents the share of reviews whose sentiment changed from positive to negative; sentiment did change
- X21 represents the share of reviews whose sentiment changed from negative to positive; sentiment changed well
- X22 represents the share of reviews whose initial associated sentiment and the sentiment of the counterfactual example are negative; sentiment has remained the same
We compute the "counterfactual confusion matrix" on the same text corpus that enabled us to perform clustering, picking 5 tokens for each review. The result is given below:

Table 2 - Actual counterfactual confusion matrix
Thus, we see that changing the 5 tokens with the highest average attention produces a change in sentiment perception in 44% of cases. In particular, the rate of sentiment change for reviews initially perceived as positive is 31% while the rate of sentiment change for reviews initially perceived as negative is 53%. The change from negative to positive seems to be better achieved with our method.
We have shown that attention coefficients can be a source of interpretability. Used in the right way, the attention coefficients allow the detection of tokens with high predictive value. They can also be used to generate counterfactual examples in order to better understand what the sentence should have been in order to be associated with an opposite sentiment. The interest of the attention coefficients is reinforced by the "counterfactual confusion matrix": The high transformation rate of the reviews' sentiments shows that the tokens selected thanks to the attention are strongly meaningful.
Next step
We plan to test other ways to generate counterfactual examples. One way would be to take advantage of the way DistilBert has been trained: the mask language modeling (MLM). The idea would be to mask the tokens with high average attention, and replace them with the tokens with the highest softmax in the "opposite cluster". This would ensure the grammatical correctness of the generated counterfactual example. Finally, the generation of counterfactual examples can have other applications than interpretability. In particular, it becomes possible to perform data augmentation in order to give more examples to a model. It can mitigate biases by balancing the sentiments of biased discriminated populations. This would improve fairness indicators while not degrading accuracy.
References
[1] VASWANI, Ashish, SHAZEER, Noam, PARMAR, Niki, et al. Attention is all you need. Advances in neural information processing systems, 2017, vol. 30.
[2] SANH, Victor, DEBUT, Lysandre, CHAUMOND, Julien, et al. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019.
[3] Hugging face library https://huggingface.co/
[4] PEARL, Judea et MACKENZIE, Dana. The book of why: the new science of cause and effect. Basic books, 2018