
1. Talk to data: a new frontier
As 2023 drew to a close, we made a strategic decision to tackle one of the most promising challenges in data science: enabling natural language interactions with databases, technically known as "Text-to-SQL." Our conviction that 2024 would be the breakthrough year for talk-to-data applications was driven by several key developments: the release of GPT-4-turbo, intensifying competition in the AI space, declining implementation costs, expanded context windows, and unprecedented market momentum.
2. Business Value
The business case for talk-to-data solutions extends beyond technical innovation. We identified 3 primary value propositions that resonated with our first customer:

Market validation has since strengthened our conviction: for instance, Uber reports a 70% reduction in SQL query authoring time through such tools, translating to an estimated 140,000 hours saved monthly (source: https://medium.com/wrenai/how-uber-is-saving-140-000-hours-each-month-using-text-to-sql-and-how-you-can-harness-the-same-fb4818ae4ea3).
3. Technical Challenges
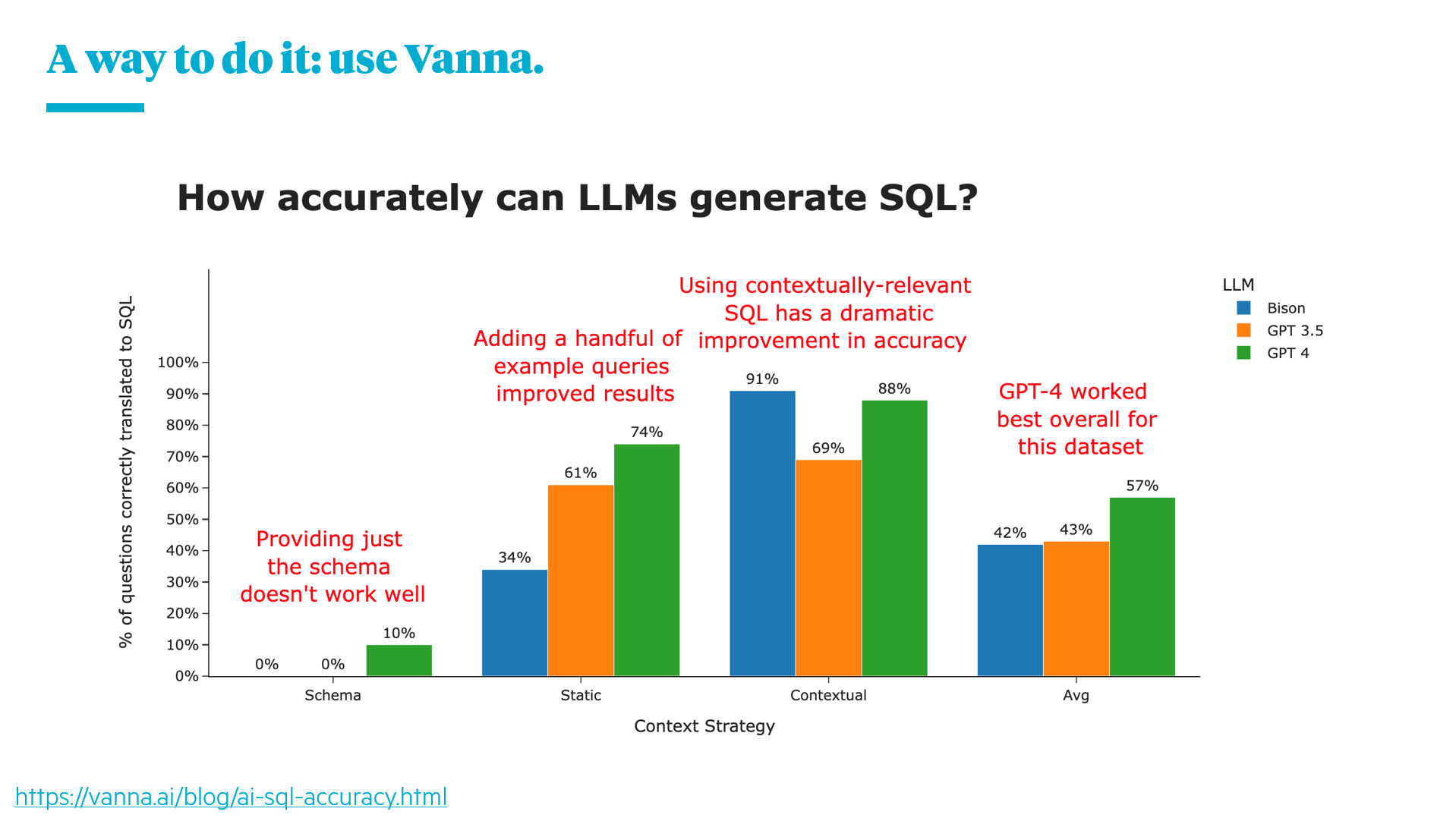
You might wonder: since RAGs have proven effective with LLMs like GPT-3.5, why wouldn't they suffice for database interactions? After all, databases are structured in tabular formats, seemingly eliminating the need for parsing, chunking, or preprocessing.
However, despite the apparent simplicity of structured databases, four significant challenges make this task particularly complex:
- Ambiguity in Natural Language: varies from one user to another, and one question can have several answers
- Complex SQL syntax: You may need nested queries, aggregations, filters and conditions
- Schema & Naming Understanding: Alignment between the user question, the format of data, the naming of fields, and then the SQL... are not trivial
- Error Sensitivity: small errors in SQL lead to invalid queries or incorrect results, unlike natural language, where minor errors are often tolerated.
4. Strategic Approach
Our initial analysis identified four potential implementation strategies, evaluated against specificity and robustness:
- A pure text-to-sql LLM
- A text-to-sql LLM enhanced by various controls & assistance
- Aggregation of data in automatically generated small tables
- A very laborious pattern extraction model to try to match natural language pieces with predefined SQL pieces
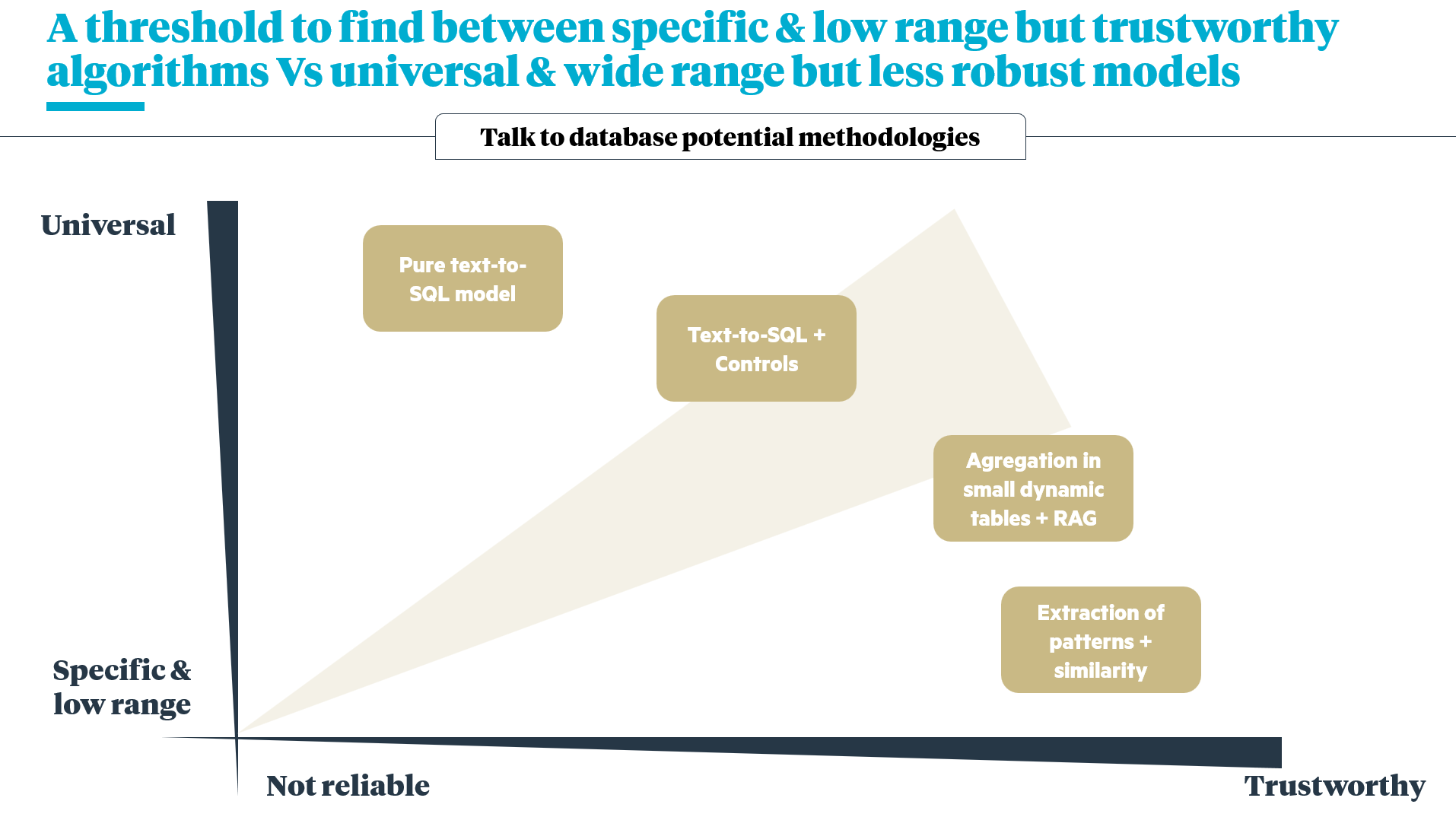
To fill in the gaps between these two axes, we chose the “text-to-SQL + controls” solution, and used the Vanna framework as our foundation to accelerate our developments.
5. Implementation Journey
Architecture & Initial Setup
To begin with, we created an architecture fitting with the client environment & the architects’ requirements. While the complete technical details are beyond this document's scope, here's a simplified overview:
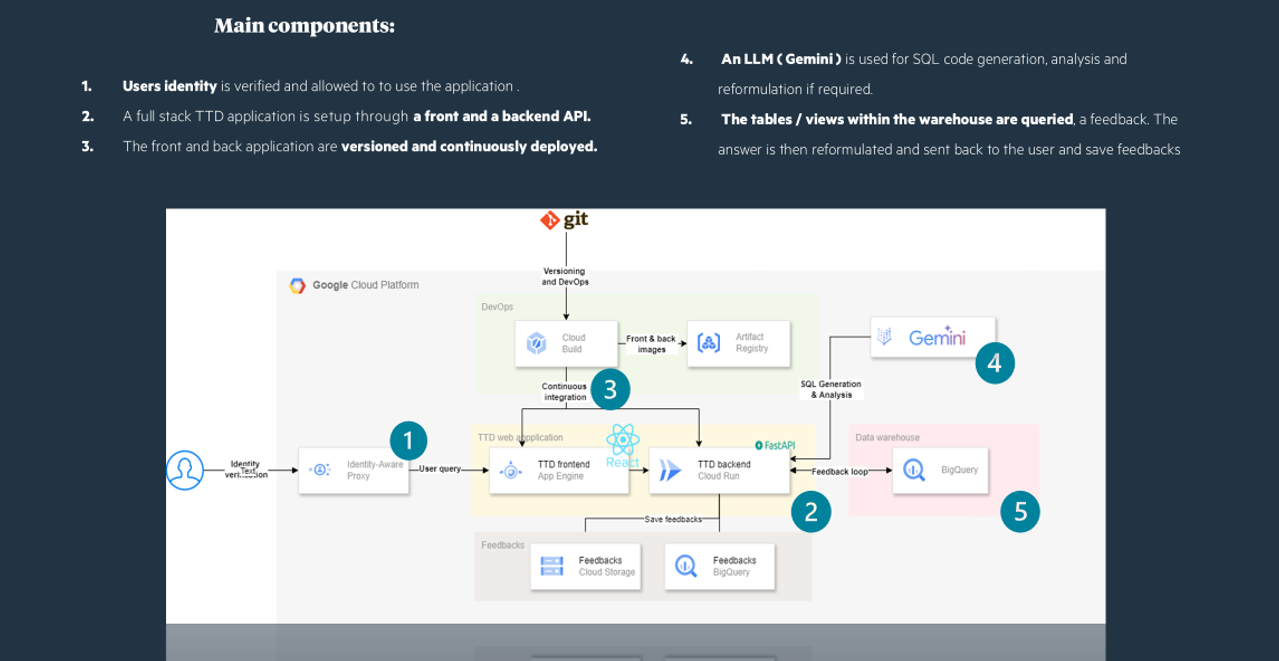
To launch our work, we reframed the business need: the customer only wanted an application that would enable them to query their database: one question, one answer, directly in the form of data.
We quickly identified a critical challenge: how could business users without SQL expertise or familiarity with the available tables verify the accuracy and relevance of the answers?
To address this issue, we immediately incorporated a natural language reformulation of the SQL query - which only addresses part of the problem, however. And to improve regularly the tool, we integrated human feedback loops through example pairs (question and SQL answer).
Our initial implementation included:
- A dockerised architecture connecting back and front via FastAPI
- Vanna 0.0.3x
- A GPT 3.5 turbo (to limit costs on iterations, which proved useful at first)
- Access to 2-3 tables in an initially fixed format
Implementation Challenges & Solutions
Our work initially consisted of testing and identifying problems, the better to reflect on them and devise solutions. Working with limited-capability LLMs highlighted the importance of robust code and precise prompting. Here are the key challenges we encountered:

We developed several solutions to address these challenges. Below are three key challenges and the solutions we developed:
a/ Problems linked to the database:
To manage problems linked to a change in the data (change of name, addition of field, modality, etc.), we created 3 types of referential that enabled us to observe and integrate table changes as automatically as possible, even when they were not communicated:
- A replica of the data dictionary (Excel) used by the data team, listing the table name, field, type, description and an example of a value.
- A configuration automatically generated from the data available at the time of generation, listing the table schemas (CREATE TABLE ...), and examples of SQL queries automatically translated into natural language, the main purpose of which is to link a word with a field in a table (list the countries France, GB and Germany // SELECT country FROM table_A WHERE country in (‘FRA’, ‘GBR’, ‘DEU’))
- A repository of field values in STRING format
These repositories do not solve the fundamental problem of data instability and communication problems between teams, but they do provide a clear picture of what is being used, enable alerts to be raised quickly, and allow the most automatic possible adaptation to changes in the databases. Because the best response is above all to have real data governance, quality controls, bodies and processes for validating and communicating changes.
b/ Problems linked to the lack of correspondence between the business language and the database language
This is the major difficulty with TTD.
There are several factors, and therefore several solutions:
Unclear questions
Example: what is the price of XXX -> no date, no distinction between new and used, etc.
Solution:
- Add default filters (e.g. most recent date)
- Choose one of several possible tables, and specify this in the SQL query reformulation in natural language.
- Solutions based on a multi-turn discussion with LLM:
- LLM points out the ambiguities of the formulation and asks for clarification
- LLM shows what related data are available, and asks for clarification
- LLM suggests a reformulation, and asks for validation before generating the SQL
Questions that are too specific
Example: ‘What is the price of X on 1 January at 1.03pm according to website Y in region Z?’ when the information is only available on average on a monthly basis.
Solution:
- In general, the LLM responds as best it can, and rephrasing allows the user to be informed of the level of detail in the response. But be careful, too much detail can lead the LLM to add aberrant filters - which again is visible in the reformulation.
- Solutions based on a multi-turn discussion with LLM (see above)
An implicit context
Example:
- User A, living in France: what is the price of XXX? (implied: in France)
- User B, living in the UK: what is the price of XXX? (implied: in the UK)
Solutions (not all integrated):
- Personalise the TTD with a simple prompt presenting the user's context
- Add default filters based on country, entity, etc.
Unclear field names
Example: field names such as ‘DL_MKT_TIME’. The description of the field allows the LLM to understand it, but the name of the field is very important.
Solutions:
- Create views dedicated to TTD
- Use a business name in the TTD code, which will be replaced on the fly by its technical name when the request is made.
Jargon in user questions
Example: business abbreviations (‘bb’ for ‘buyback’, etc.).
Solution:
- Specific jargon must necessarily be given to the LLM, either upstream (FT) or in the document base (which feeds the prompt).
- Hybrid search can be used to retrieve specific business vocabulary that is not well represented in the latent vector space.
Table formats (aggregation, filter, etc.) of which the user is unaware, leading to complex or impossible queries
Example: ‘what is the average selling price of X’ on a table aggregated by shop (requiring a weighted average).
Solutions:
Information & instructions:
- The description of the tables and fields must be clear about their level of aggregation.
- More examples
Safeguards:
- Identify certain patterns in the query, then raise an error with a corrective message for the LLM
- Even on-the-fly replacement of certain operations
Specific field formats
- Example: two fields for a single word, several words in one field value, etc.
- Solution: in this case, the best solution is still to change the data. If this isn't possible and TTD doesn't work as expected, you can use ad-hoc prompts and fairly open SQL queries (e.g. ‘LIKE’ instead of ‘=’).
c/ Performance drift & speed of development
To test the performance, a dedicated team of users asked regularly new questions (not the golden questions) to the tool on various tables & topics, the metric being simply here the rate of correct answers on answerable questions.
The final difficulty, linked to the high error sensitivity of text-2-sql, was its initial instability during development. To remedy this, two minimum solutions quickly became apparent.
- Any new change must be accompanied by a drift measurement (loss of reliability on questions that have already been mastered).
- By adding tables, new prompt elements can be confused with older ones, which were not designed at the same time. To counter this, a table assignment mechanism upstream of the chain should enable the LLM to be directed towards a list of candidate tables.
6. Future Outlook
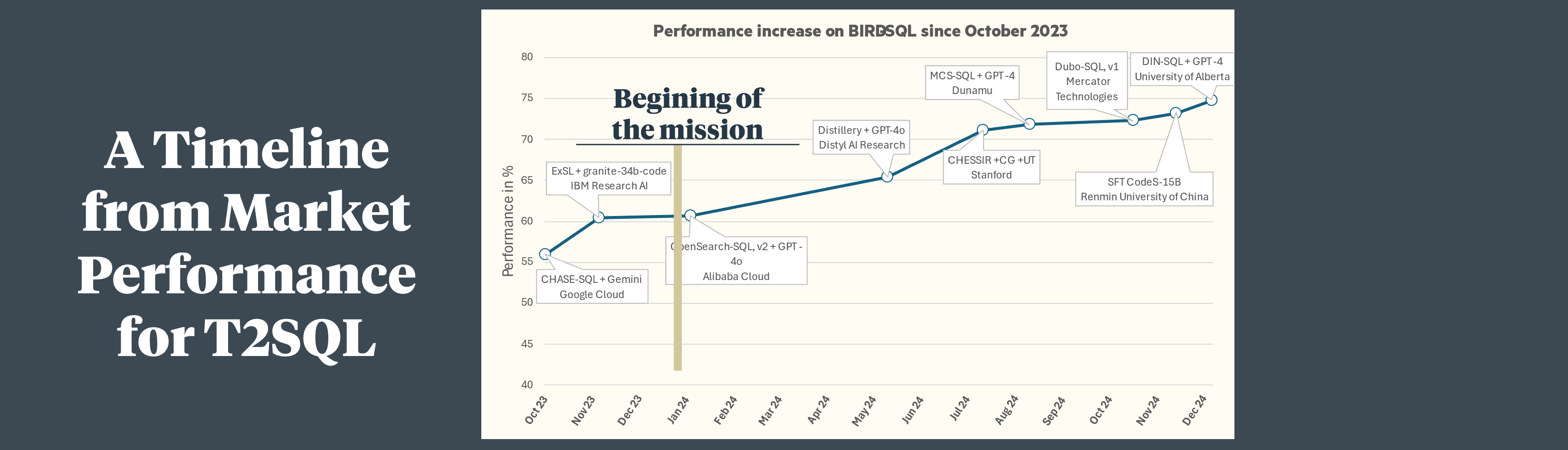
The landscape of talk-to-data solutions continues to evolve rapidly, with major players like Databricks and Google introducing interesting offerings. The Bird SQL benchmark continues to fill up with new records, and LLMs have greatly improved their code generation, thanks in particular to the ‘test time compute’ approach.
But our experience shows that all these use cases will require the following fundamental elements: excellent data governance, a solid business sense on the part of the players responsible for maintaining text-to-SQL-based products, and well-parametrized tools to ensure robust responses - expertise and solutions that we've developed and proven to be consistently valuable.
The future of text-to-SQL applications depends not just on technological advancement, but on the thoughtful integration of these fundamental elements.